



The death of RAG
RAG vs Long Context Length

Good morning everyone!
Today, we’re diving into “the death of RAG.”
Many clients told us (Towards AI), “But why would I use RAG if Gemini can process millions of tokens as input?”
So, is RAG dead? That's what we investigate in this iteration...
This issue is brought to you thanks to Yandex.
1️⃣ The evolution of LLM compression methods: from QuIP to AQLM with PV-Tuning (Sponsor)

While large language models open up a world of possibilities, they can also be incredibly expensive and complex to deploy. That's why researchers are racing to find ways to compress these models without sacrificing performance.
Learn about the evolution of extreme LLM compression methods in their latest article.
Spoiler alert: a brief "rivalry" between two research teams led to scientific breakthroughs.
2️⃣ RAG vs Long Context Length
Before we start, this is a piece I made along with two friends working at Towards AI for our weekly High Learning Rate newsletter (which you should follow), where we share real-world solutions for real-world problems, and do our best to teach to leverage AI's potential with insider tips from specialists in the field, every week.
With the rapid advancements in LLMs and especially their growing context window size (input text size), many people now think doing RAG with Long Context models is no longer necessary. For example, OpenAI’s gpt-4-0314 model from March 14th, 2023, could only process up to 8k tokens. Now, gpt-4o can process up to 128k tokens, while gemini-1.5-pro can now process up to 2M tokens. This is ~3,000 pages of text!
We'll demystify the differences between RAG and sending all data in the input, explaining why we believe RAG will remain relevant for the foreseeable future. This will help you determine whether RAG is suitable for your application.
About RAG…
As a reminder, RAG is simply the process of retrieving and adding relevant information to an LLM prompt. The added information should contain relevant information about the initial user prompt.
We can retrieve this information by searching through external data sources such as PDF documents or existing databases. This method is most useful for private data or advanced topics the LLM might not have seen during its training. You can learn more about RAG here.
From now on, we assume you are familiar with such systems.
When is RAG good?
RAG is an excellent technique for handling large collections of documents that cannot fit within a single LLM context window. This approach makes it simple to add custom information to a database, enabling quick updates to the LLM's responses (vs. retraining the model). So, RAG is ideal for incorporating new knowledge into an LLM without the need for fine-tuning. For instance, it's particularly useful for integrating documentation and code snippets that often change.
Contrary to some popular beliefs, RAG systems are fast and accurate. Queries to a database with multiple documents are processed quickly due to efficient document indexing methods. When dealing with lots of data, this search process is much lighter compared to sending all the information directly to an LLM and trying to “find the useful needle” in the stack of data. With RAG, we can selectively include relevant information to the initial prompt. Thus reducing the noise and potential hallucinations. As a bonus, RAG allows for the use of advanced techniques and systems, such as metadata filtering and hybrid search, to enhance performance and not solely depend on an LLM.
The main “downside” of RAG is that the quality of the response heavily relies on the quality of the retrieval. Since we determine the context, missing information can occur if the retrieval process is inadequate. Building a good RAG pipeline can be complex, depending on the data and the type of questions the system has to answer. Thus, it is important to evaluate your RAG system properly, which we covered in a previous iteration.
About long context length…
When we talk about “long context length,” we mean models that can process a large number of input tokens, like gemini-1.5-pro, which recently got upgraded to process up to 2 MILLION tokens.
Allowing for more input tokens lets the model reason over extended text passages, which can be a game-changer for many applications, as you can send whole books directly in your prompt and ask questions about them.
Before we dive into the topic, here’s a list of the current models and their respective context windows:
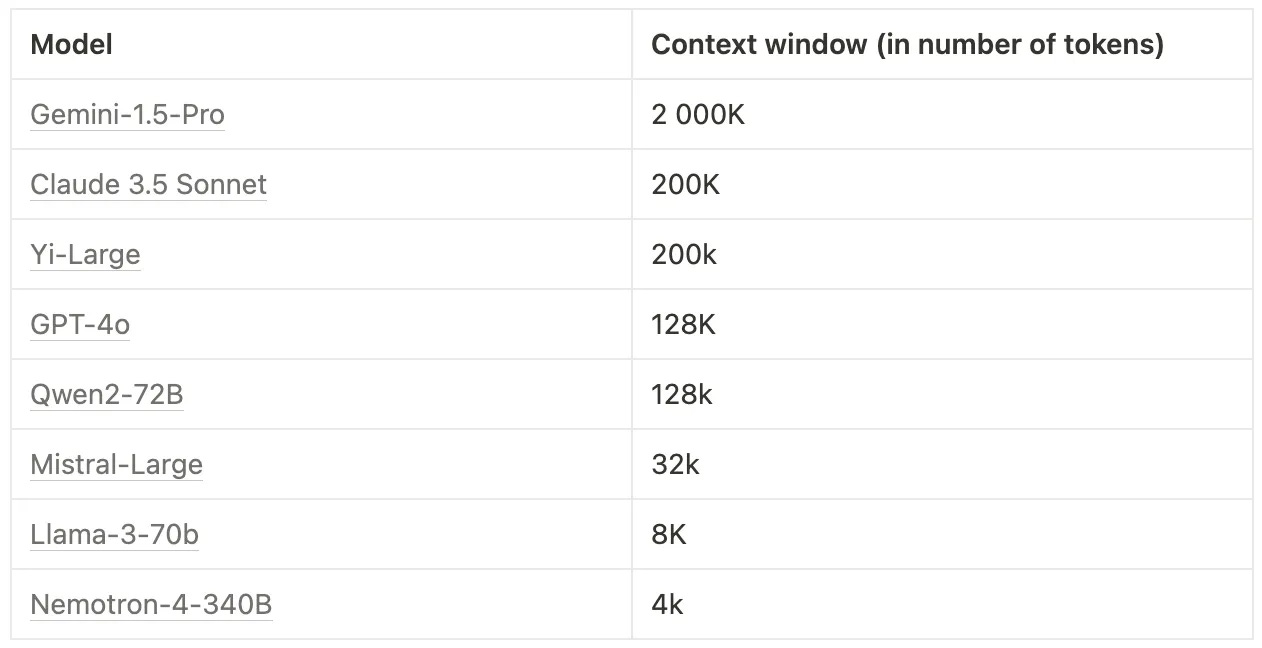
When is long context length good?
As we briefly mentioned, working with a long context is good when your task requires the LLM to examine large amounts of data simultaneously, and a long processing time is not an issue. These models process up to 2M tokens through an iterative process with a smaller amount sequentially processed until the whole input length is completed, saving knowledge from each sub-part in an encoded format.
For example, using long context is ideal when trying to understand an entire new codebase. The LLM will see every file and every line of code and will be able to answer any of your questions. Check out code2prompt. A command-line tool (CLI) that converts your codebase into a single LLM prompt with a source tree, prompt templating, and token counting.
Long context is particularly useful when dealing with one-off texts, including articles, podcast transcripts, books, manuals, etc… Anything that is too long for you to read (depending on your laziness) but where you will only have questions about it in the near future and not come back to this piece of knowledge or add to it. It will be a powerful and extremely quick MVP (or quick one-off deals, just copy-paste text), but it is more expensive to use, weaker, and less sustainable in the long run than a functioning RAG system.
Existing Evaluations of Long Context Length
Since we’ve already covered how we evaluate RAG systems, we wanted to say some words on long context evaluation…
New LLMs usually report performances related to context windows using the Needle in a Haystack evaluation**.** The "needle in a haystack" evaluation for LLMs is a methodology shared by Greg Kamradt. It evaluates LLMs’ ability to retrieve specific information from long texts. It involves embedding a particular piece of information (the "needle") within a larger body of text (the "haystack") and testing the LLM's capability to retrieve it accurately. For example, we will ask it to retrieve a random sentence added within a book, like adding the random sentence “Pineapples are a necessary ingredient to make the best pizza possible” in a Dostoievsky book, and then ask the LLM “What is a necessary ingredient for making the best pizza possible?”, and compare the output with the original sentence.
It is also currently too easy as the latest Gemini 1.5 Pro found the embedded text 99% of the time in blocks of data as long as 1 million tokens. In order to help, researchers created the Needle in a Needle Stack evaluation pipeline, which Gemini 1.5 Pro is also the current best**.** It is a more challenging evaluation of the same flavour where the LLM must retrieve specific information within a large dataset of really similar items. Here, the prompt includes thousands of limericks (A humorous five-line poem). The increased difficulty comes with the bigger similarity between the ‘needle’ and the rest of the text, as all limericks share the same structure.
While useful, we don’t find it comprehensive as it only tests the retrieval capability of LLMs without assessing how well the model uses the information. More precisely, they compare the output and the needles but not how the LLM is able to use the needle as in RAG systems.
End of the long context length interlude.
So, is RAG Going Away?
No. While the increase in context length reduces the need for RAG, it remains advantageous in many scenarios. By retrieving specific information rather than processing vast amounts of text, and enhancing efficiency and speed. RAG shines when (1) dealing with large datasets, (2) where processing time is critical, and (3) when the application needs to be cost-effective. This is especially important when utilizing an LLM through an API, as sending millions of tokens for every request to provide context can be expensive. In contrast, retrieval is extremely efficient and cheap, allowing you to send just the right bits of information to your LLM.
However, there are instances when using a long context model is more beneficial, such as with smaller datasets (like one or two PDFs), avoiding the need to create a RAG pipeline. Additionally, if you don’t handle a lot of prompts per hour, using a long context model can be more cost-effective if you consider the building costs.
So, both approaches have their place depending on your application's specific needs and constraints. In the end, both methods add information to the initial prompt. In RAG, only the relevant information is added to the prompt, limiting hallucination potential and noise, contrary to the long context, where you add all the information available, putting more load on the LLM itself.
RAG is ideal for customer support systems and real-time data integration, while long context models are best for complex single-document analysis and summarization tasks.
A quick, fun experiment…
We’ve decided to run a fun experiment comparing our RAG AI tutor with long context using Gemini 1.5 Pro. We tested using 2M tokens from the HugginFace Transformers documentation on both our RAG system and Gemini, and it appears that both were able to give us the desired answer, though Gemini took well over a minute to start replying, while the RAG chatbot replied instantly and gave us the link to the specific page for more information.
To finish, here’s a summary of the key points in a table comparing both RAG and long context length for various characteristics:
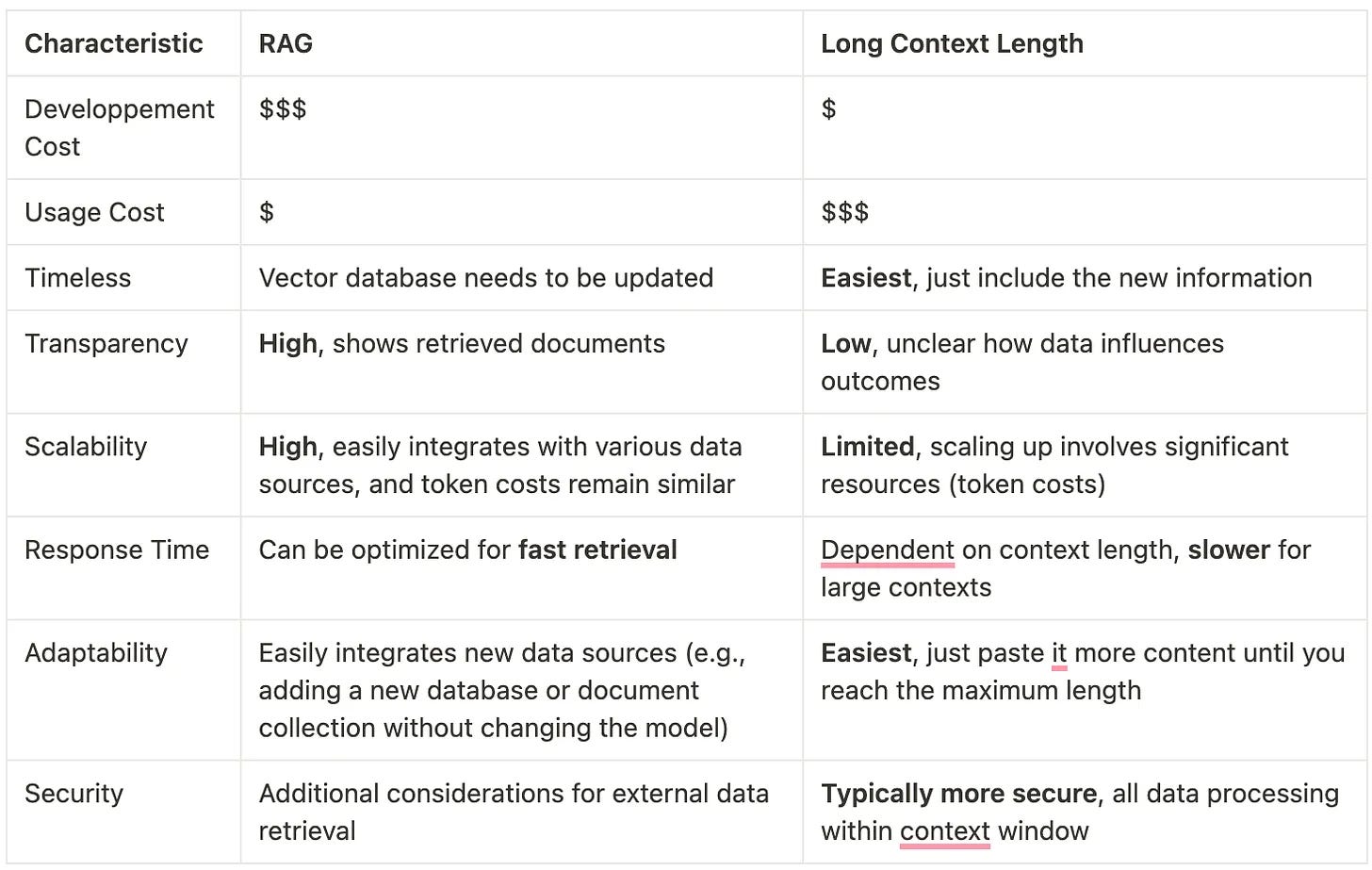
Bonus: Cheat Sheet: RAG vs Long Context Length
If this iteration wasn’t enough, here’s a cheat sheet we came up with to help you further in making a decision:
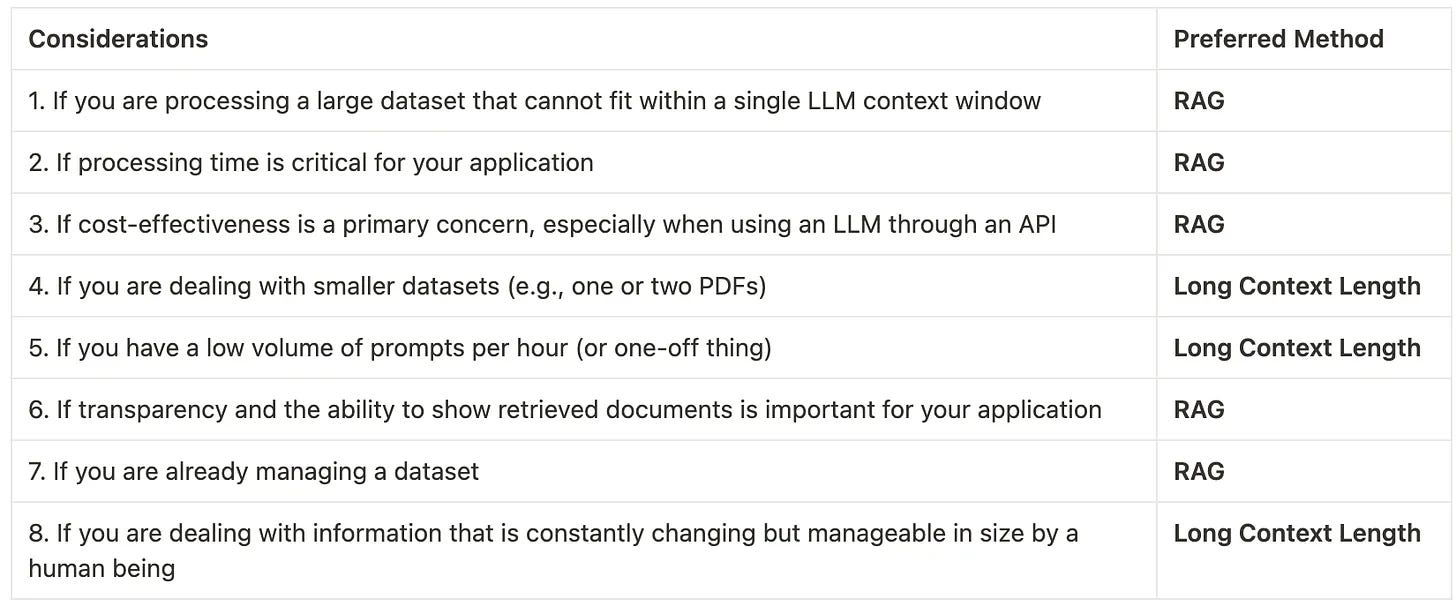
And that's it for this iteration! I'm incredibly grateful that the What's AI newsletter is now read by over 17,000 incredible human beings. Click here to share this iteration with a friend if you learned something new!
Looking for more cool AI stuff? 👇
Looking for AI news, code, learning resources, papers, memes, and more? Follow our weekly newsletter at Towards AI!
Looking to connect with other AI enthusiasts? Join the Discord community: Learn AI Together!
Want to share a product, event or course with my AI community? Reply directly to this email, or visit my Passionfroot profile to see my offers.
Thank you for reading, and I wish you a fantastic week! Be sure to have enough sleep and physical activities next week!
Louis-François Bouchard, CTO and co-founder at Towards AI
From what I understand from people working with content at scale, neither of these will be effective on their own. Knowledge graphs and high quality, structured content is key in both cases.