

When to Use GraphRAG
GraphRAG: What, When, Why, How...

Good morning everyone! In this iteration, we focus on the new hype in LLMs: GraphRAG.
GraphRAG is a powerful extension to the Retrieval-Augmented Generation (RAG) stack making a lot of noise thanks to Microsoft and LlamaIndex’s contributions.
But the question remains: Should YOU be using it?
To answer when we need it, we first need to understand what it is...
This issue is brought to you thanks to Yandex.
1️⃣ From QuIP to AQLM with PV-Tuning: LLM compression at the extreme

The trade-off between large model size and computational efficiency has long been a challenge in deploying language models. The research community has been looking to reduce model size by 8 times, down to 2 bits. This year, they found a way to do it without sacrificing model performance.
Here's the story behind the evolution of extreme LLM compression methods.
2️⃣ GraphRAG
Before we start, this is a piece I made along with two friends working at Towards AI for our weekly High Learning Rate newsletter (which you should follow), where we share real-world solutions for real-world problems, and do our best to teach to leverage AI's potential with insider tips from specialists in the field, every week.
What is GraphRAG?
GraphRAG enhances traditional RAG by incorporating knowledge graphs into the retrieval process. Instead of relying solely on vector similarity (comparing numbers to find the most relevant ‘similar’ matches), GraphRAG extracts entities and relationships from your data, creating a structured representation that captures semantic connections. Semantic means understanding the meaning behind words or data, in a specific context, not just their literal definitions. This approach allows for more nuanced and context-aware retrieval, potentially leading to more accurate and comprehensive responses from your LLM.
A knowledge graph is simply a structured representation of data that captures entities and their relationships, allowing for better understanding and retrieval of information.
When to Use GraphRAG: It's All About Your Data
The decision to implement GraphRAG heavily depends on your dataset's nature. If your data is rich in interconnected entities and relationships - think academic papers (many cite each other and progress in time), corporate knowledge bases, or complex historical records - GraphRAG might outperform regular RAG. It’s perfect for capturing and leveraging these connections, enabling more informed and contextually relevant retrievals that standard RAG might miss.
User Queries: Complexity is Key
GraphRAG is most useful when dealing with complex, multi-faceted queries that require traversing multiple pieces of information (or asking meta-questions about the data itself, such as “How many papers have been published between 2010 and 2020 about RAG” (Spoiler: 0)). If your users frequently ask questions like "How does the theory proposed in Paper A relate to the findings in Paper B, and what are the implications for field C?", GraphRAG's ability to navigate and synthesize information across your knowledge graph becomes essential, whereas regular RAG might just bring out the most relevant chunks to some of these topics, and the LLM might hallucinate the rest.
Data Storage Considerations
While GraphRAG can work with various data storage systems, it's particularly powerful when your data is already structured in a graph-like format or can be easily transformed into one. Graph databases like
When to Skip GraphRAG
Despite its power, GraphRAG isn't always the best choice. For simpler datasets (and single-faceted queries) with straightforward relationships or when dealing primarily with structured text documents, traditional RAG or advanced search methods might be more efficient. Advanced methods include hybrid search, which combines vector similarity and keyword search, or techniques that use metadata filtering to narrow down search possibilities.
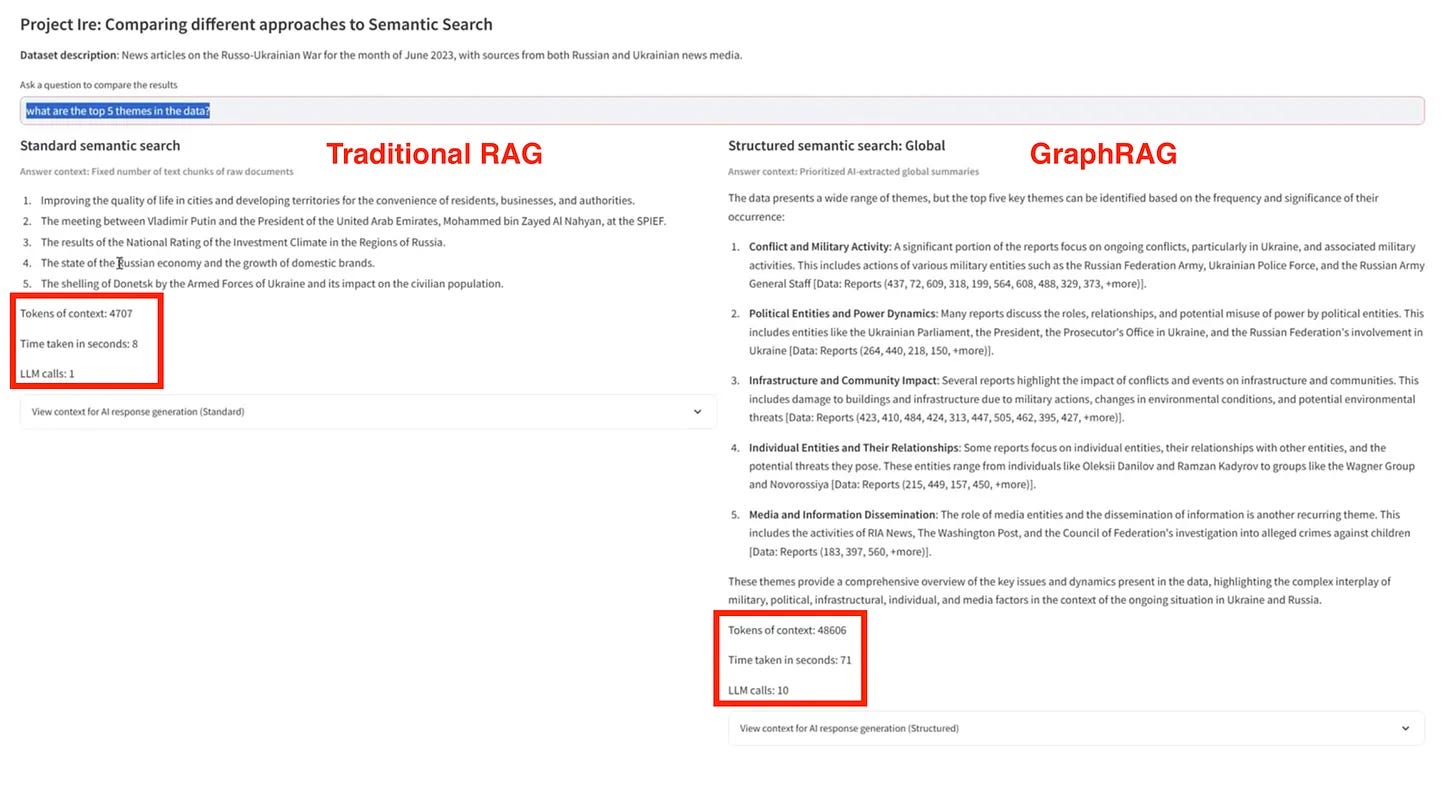
Even though the results are more interesting, GraphRAG requires almost 10x more time and 10x more tokens to produce. Make sure you need it!
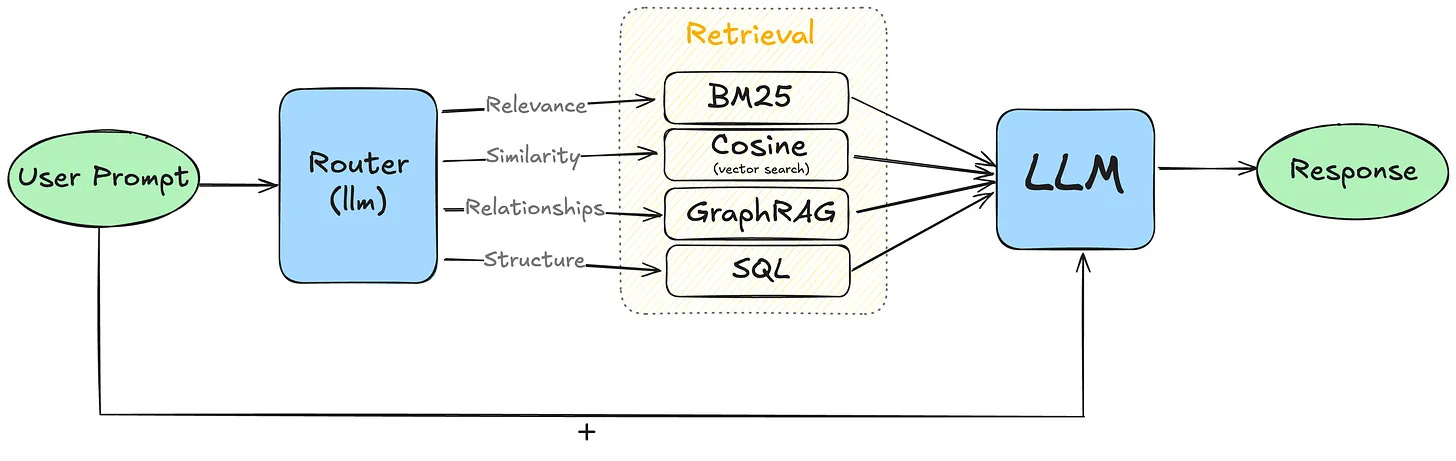
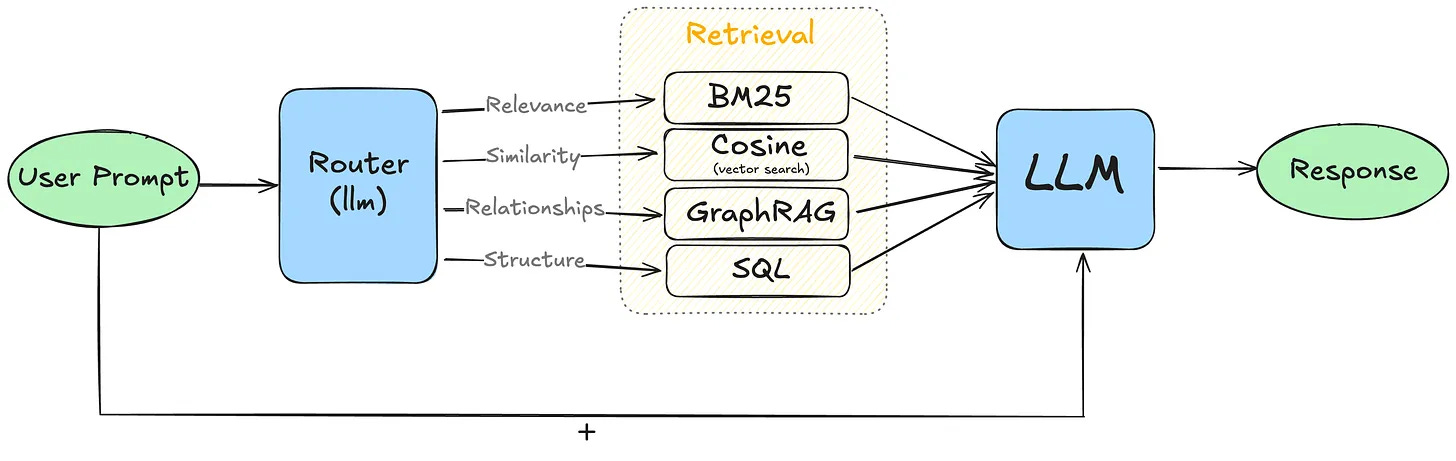
Combining Approaches: The Router Strategy
In real-world applications, a one-size-fits-all approach rarely works. Consider implementing a router system that can dynamically choose between GraphRAG, Advanced RAG, text-to-SQL retrieval, or any other search method based on the query type and available data. This flexible approach ensures you're using the most appropriate retrieval method for each specific query, optimizing both performance and accuracy. You will need a good base LLM and prompt to re-orient your queries to the right retrieval system.
TL;DR: GraphRAG - Powerful but Not Universal
GraphRAG offers a significant improvement in information retrieval capabilities for complex, interconnected datasets and queries requiring deep relational understanding. However, it comes with increased complexity and resource requirements. Evaluate your specific use case, data structure, and query patterns carefully. For many applications, a combination of retrieval methods, orchestrated by a smart router, will provide the best balance of performance and flexibility.
And that's it for this iteration! I'm incredibly grateful that the What's AI newsletter is now read by over 20,000 incredible human beings. Click here to share this iteration with a friend if you learned something new!
Looking for more cool AI stuff? 👇
Looking for AI news, code, learning resources, papers, memes, and more? Follow our weekly newsletter at Towards AI!
Looking to connect with other AI enthusiasts? Join the Discord community: Learn AI Together!
Want to share a product, event or course with my AI community? Reply directly to this email, or visit my Passionfroot profile to see my offers.
Thank you for reading, and I wish you a fantastic week! Be sure to have enough sleep and physical activities next week!
Louis-François Bouchard
I’m beginning to think that any content at scale should be structured… so that we can effectively use GraphRAG.
So let’s structure content from the very beginning!